
Dev Diary 14: Thoughts about server architectures
In this dev update, as we get close to feature freeze, Brian shares some screenshots of the new UI in testing and muses about server architectures.
A FAIMS 3 Poster (and general project update) at eResearch Australasia
Penny and Jens are busy this week as eResearch Australasia in Brisbane, presenting our poster (https://osf.io/5karu/). I am told, that it was ‘Highly Commended’ for condensing a lot of information onto a single poster and providing all the metadata.

Did you see our poster at eResearch Australasia 2022? Tell us what you thought!
Dev Update
The major news as our development period draws to a close is sixfold:
We have started to commit parts of our UI Refresh
We are working on better visualisation and user experience around relationships
We have demonstrated branching logic
We now support Google OAuth2 logins.
Regression testing on our iOS build has found no novel bugs.
We have basic QR code parsing working!
We have about 1 week left1 until feature freeze and so we are gliding2 to the pragmatic end of our development time for this stage of the project. Still, have some screenshots:
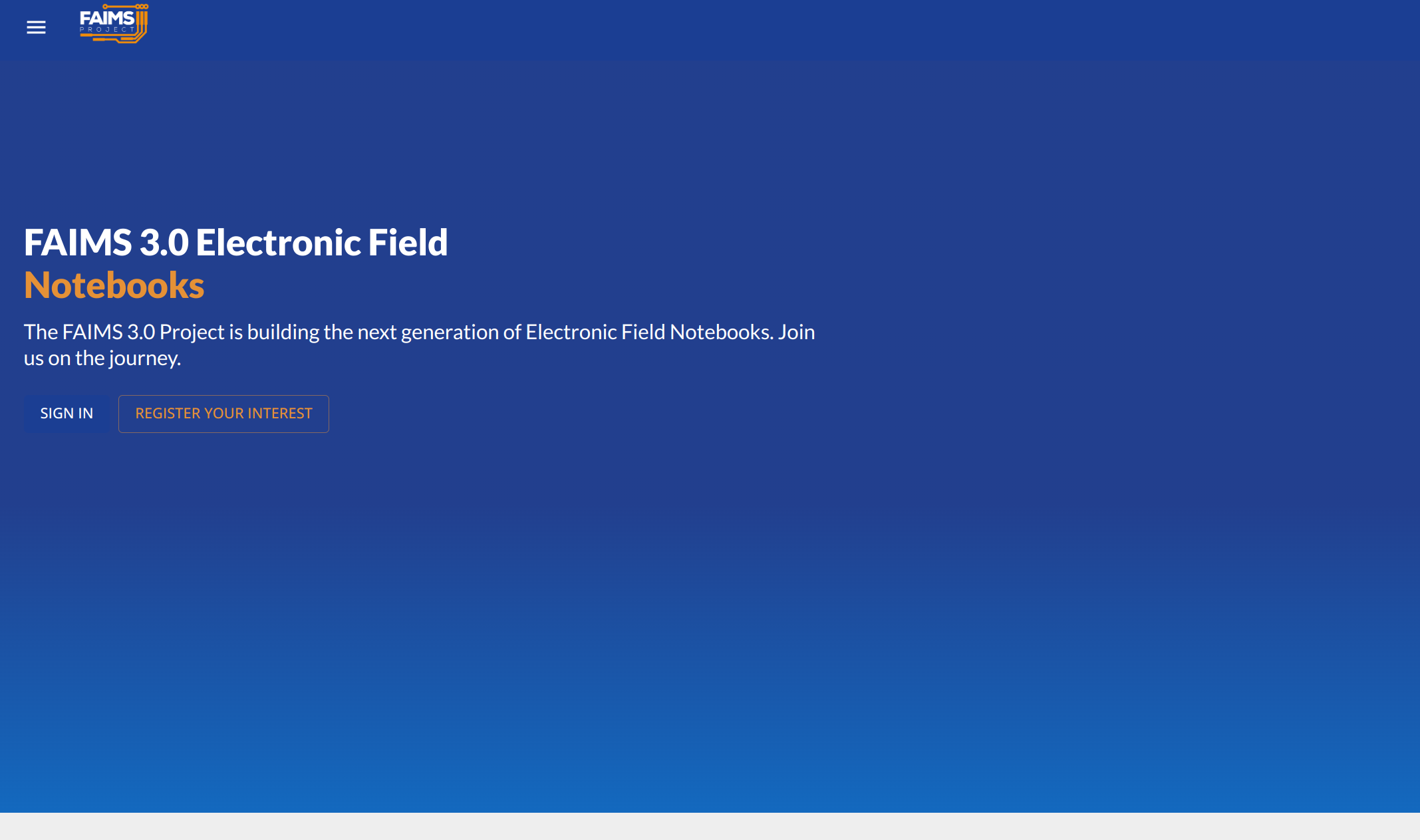
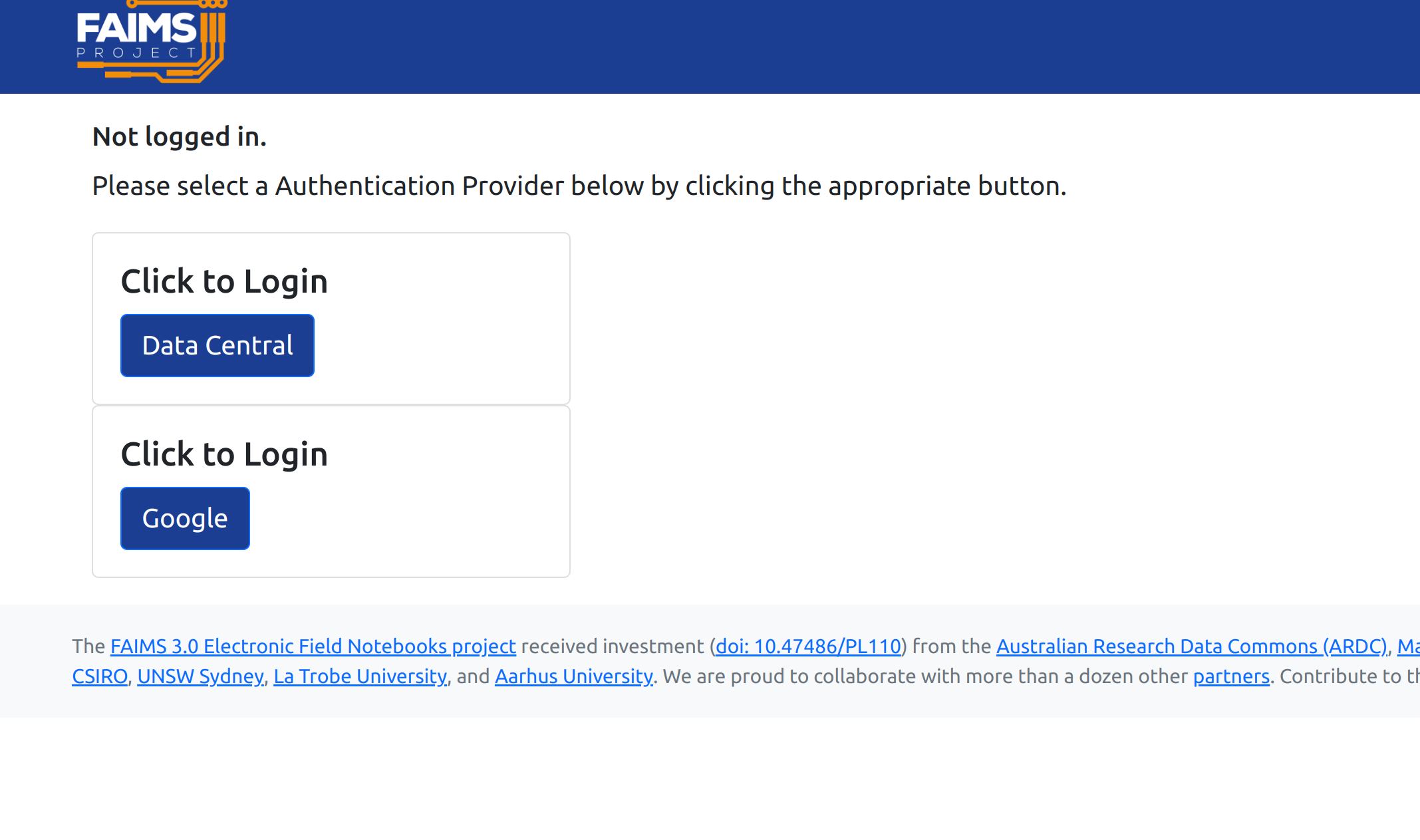

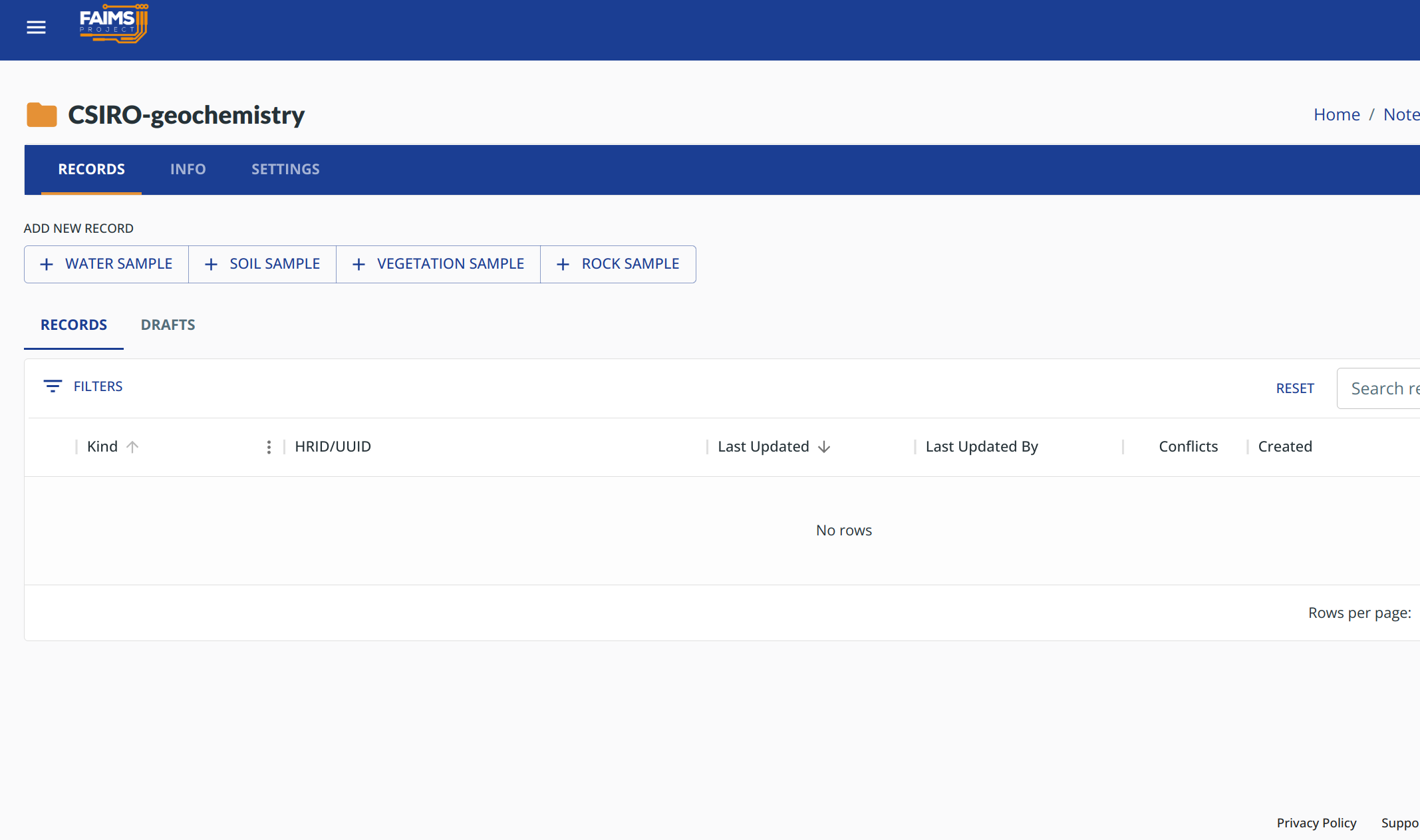
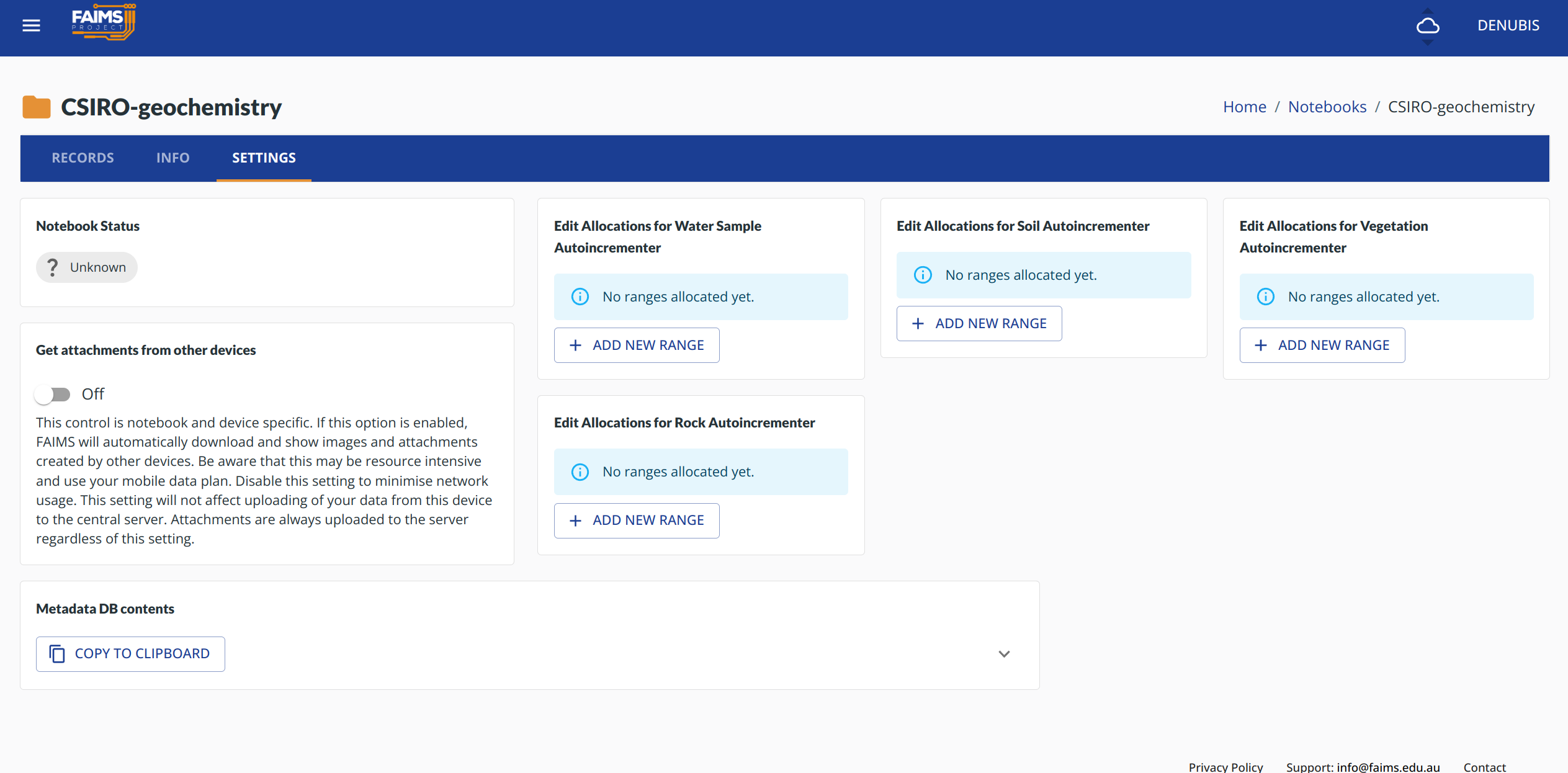
Progress!
We will be talking about our 2023 plans in another blog post.
Articulating thoughts about server architectures
My thoughts around our architecture design, inspired by A Brief History of Kubernetes, Its Use Cases, and Its Problems and a conversation we had with an amazingly knowledgeable colleague at CSIRO.
I have spent my “free time” in the last week trying to move our present set of Docker containers into a better and more sustainable architecture. We have three major components:
The FAIMS Application. This is either a static site or a natively compiled app.
CouchDB. It’s just CouchDB with minor configuration.
FAIMS3-Conductor — a lightweight authentication and role-management server. It provides the JWT token to FAIMS to be able to talk directly to Couch.
At present count, I have (about) 7 instances of the above set running on two machines. Each component has a Dockerfile and configuration of the components is handled through docker compose files to define how the three containers relate to each other, docker compose files using `extends` to implement a server-specific design, and environment files holding necessary variables per instance. The major complication with deploying FAIMS is key-generation and sharing between components, necessitating a bash script to orchestrate the orchestration layer.
Right now, the instances are on two VMs running on a rented server on campus. Bash scripts and ssh provide a pragmatic and comfortable reality. This reality is mirrored by our app deployment “strategy” wherein I have a bunch of shell scripts calling Fastlane when I need to deploy a specific Android or iOS build.
All of the above makes me a bottleneck with a bus factor of 1. This is a bad number. Given that Penny and I will be on leave throughout December and January — we will have an experimental validation of that factor arriving soon.3 As such, as the weather warms, thoughts turn to leave, and we exhaust our current development budget, system architecture and design becomes a more pressing concern.
Tilting at Kubernetes
")
Thus, the obvious4 next step would be to use Kubernetes to fully automate deployment of all systems and servers in a scalable fashion to be cloud-provider independent and reduce system administration load.
Yes, I can hear you laughing from here. I was younger and more naive two weeks ago. You can stop laughing now. I should have listened when a close friend told me how much more than me a Kubernetes engineer makes.5
Here is what I’ve figured out so far. My confidence level in what I'm saying is: "Roll for a sanity check." Kubernetes6 is a platform for declaring how ephemeral containers (Pods) should behave with regards to each other in a Service with specific deployment options committed as their own file. It is infrastructure as code. Changes to running machines are achieved through changing the deployment yaml file.
I must admit that I’ve not spent so much time on an endeavour with so little success for some decades now. Trying (and ultimately failing) to get a minimum viable example deploy over the moments of free time and no-focus over the last two weeks reminded me of some of the more trying times as an undergrad.
In conversation with a colleague at CSIRO yesterday, he revealed that Kubernetes can be powerful, but we should:
Expect to employ a full time engineer to manage any Kubernetes infrastructure we have; and
Only use Kubernetes when our system administration load becomes too complex for our current tools.
Here are some choice quotes:
Plan to use "Kubernetes for a scalable base load with everything running, with burst workloads" and "If your base load is closer to 0, Kubernetes is harder to justify the cost of."
Effectively, it’s an amazing tool for scaling out complex infrastructure. The folks at https://bioinformatics.csiro.au/variantspark/ achieved amazing efficiencies at scale with Kube. But it was an always-on complex workflow that already had significant amounts of system administration and load being thrown at it. Trying to go from “a few shell scripts” and a load of “4 projects have used us” to “a successful Kubernetes” deploy was unwise.7
"We'll need to hire someone to maintain a Kubernetes cluster" and "There are plenty of people who have gone backwards from Kubernetes"
Our very kind colleague provided useful veteran knowledge and expertise as to the minimum necessary buy-in needed to do anything useful with Kubernetes. While very powerful, it’s a powerful tool best employed when needed, rather than at the start of things.
I’m sharing these thoughts here so that other academic DevOps people wearing many hats may learn from my mistakes.
Current thoughts
I’m procrastinating from actually building out some test deployments on The Cloud: Conductor as a serverless appliance, our app as a true static site on Github Pages, and a CouchDB container where I can’t simply reach out and touch it from the shell.
Once I build those demonstration layers and prove that the conductor startup time is sufficient for us to be able to offer it as a serverless container, it was suggested that I look at tools like Terraform to progress down the infrastructure-as-code route without trying to go from 0 to 60 in negative time and non-euclidean space.
Any thoughts as to other useful tools that I really should have already had known about?
What I’m reading
Many tributes to the late Bruno Latour:
The Case For, and the Case Against, “The Case Against Education”
Short story: Lost and Found by M. L. Clark
Short story: Holiday Horrors: Feast or Famine Rulebook
Short story: Ten Steps for Effective Mold Removal
A New Topography of Philosophy: Analytic, Continental, and Philosophy of Science

I wrote 2, then checked the date because “surely we have more time until Halloween.” While I was correct that I was incorrect…it was in the wrong direction.
c.f. plummeting. https://www.bmj.com/content/363/bmj.k5094
Eh, I’m going to go with Carnap’s confirmation on this one — there is no particular demarcation between science and pseudoscience when investigating a bus factor.
….to… some…
A quite significant amount.
The key and gate — an eldritch horror beyond our ken.
Unwise in the fashion similar to that experienced by novice street racers when their car’s transmission is on the asphalt due to poor gear choices.
For more news, subscribe!

