
Dev Diary 13: Diagrams explaining the process and technology of our electronic field notebook app… thing…
We’ve been working on a pitch for something seekrit. Besides ██████████████ ██████████████, we also made some diagrams describing the system using graphviz. Seems worth blogging about, so here goes.
Dev update
But first, a dev update! Besides quite a lot of devops work on CouchDB and our conductor integration (delayed by the events of the last few weeks), we’ve been:
🎉 We just got authentication working on the compiled iPad app! (Still quite a lot of testing to do, but this was a problem that has plagued us for months.)
Whacking through bugs;
Testing branching logic (the ability to control field and view visibility conditional on prior values);
Working on improvements to form-relationship navigation (to make both parent-child and linking relationships more usable); and
Doing quite a lot of work on the UI.
We’ve also redoubled efforts for iOS integration. We have … 6… weeks left until feature freeze1.
Data Collection Workflow Discussion
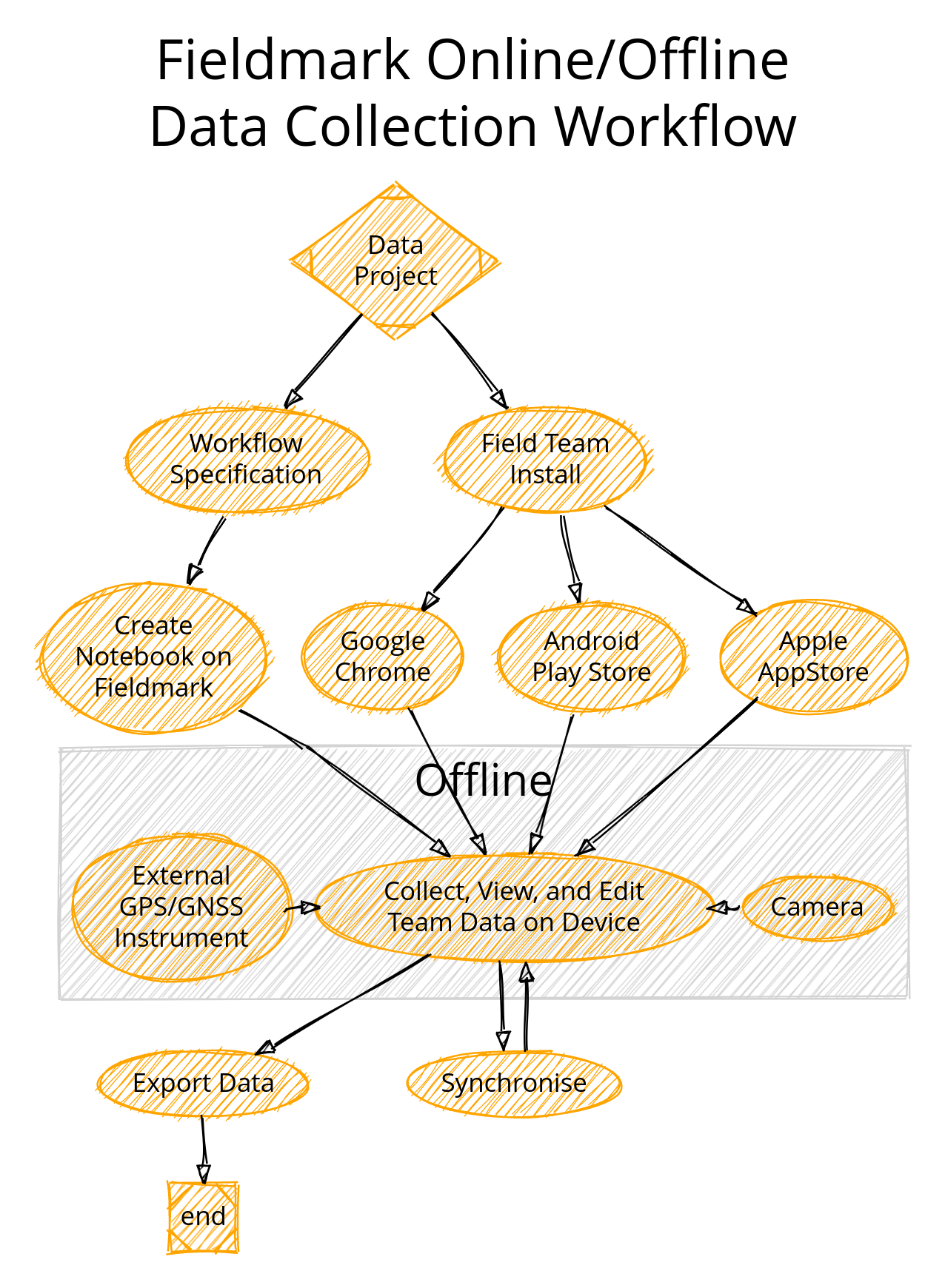
As a preface, these diagrams are Graphviz specified diagrams produced by the Sketchviz online service and saved as github gists. We live in a strange world. (The ‘sketchy’ line-rendering is a function of a svg transform of the sketchviz app-presentation.)
Fieldmark starts with workflows, preferably established ones. One thing we’ve noticed is that more data and more useful data is produced from a project that knows what it wants. A theoretical form, or one copied from a standard template, is seldom used in its entirety, and often omits important (meta)data, which accumulates as implicit knowledge. The complexity of implementing unused fields is wasted, while ‘missing’ fields degrade data.
The field director (or delegated person) makes the notebook specification. One branch, planning, makes the workflow to suit the data needed. We don’t support multi-person notebook editing at present, so one and only one person should be responsible for the notebook design. This limitation will change in the future.
We then deploy the notebook on appropriate servers. This process is, at present, entirely manual and mediated by Brian. We look forward to automating this in the next 6 weeks.
At the same time, the team should prepare to record data. The team can deploy Fieldmark onto several devices through various channels: Android, web, and iOS2. As they are deploying devices, the team should also be registering and communicating their usernames to (again) Brian. This process of adding users to a notebook is also something we plan to automate really soon now.
[Everyone signs in, and does' pre-field prep, not pictured]. I very carefully left the boring 'pre-field prep, pre-field prep-prep, and meetings about meetings to prepare to prep for fieldwork'3 out of the above diagram. But yes, some time between notebook instantiation and going to the field, everyone needs to sign in and make sure their tablets have the notebook. Pragmatically, this can be done before leaving for the field, in the field house, or on a wireless 4G dongle4.
The offline zone.
Once synchronised, data collection can begin. Users can bring tablets and phones and laptops5 out into the field to collect data. Specifically, we support the full CRUD: record creation, retrieval, updating, and deletion. We’ve demonstrated using external Bluetooth dongles and support onboard camera + external file attachments for photos and multimedia. Thus, we have a team, while offline, collecting geospatial and multimedia data in addition to structured data as specified in their workflow.
Useful aside on the nature of offline. One of our fundamental features of FAIMS 2, and one of the things we’re working towards in Fieldmark,6 is the ability to use a local network for syncing and other 'online' actions. We hope that with a Raspberry Pi, some solar cells and dongles, researchers will soon7 be able to bring a local area network with them, past basecamp and onto a dig or survey or sampling trip. Just today I set up replication between two of our CouchDB servers to aid in tracking down a performance bug, so all signs point to this offline-online capability being possible and useful. It would be a step up from a NUC in a pelican case mounted in a truck.
Returning to … the online zone
It is likely that for the next year or so, exports will be accomplished through custom scripts, rather than through functionality built into the app itself. The rationale for this is:
Tradition! Specifically, in FAIMS 2, we were able to accommodate many data formats by having the server run scripts8 to extract data, tweak and transform it in any one of many ways, then export a compressed file with many data files, photos, and folders within. This data-flexibility is one of our main selling points, but to accomplish it--we (I) will need to tweak data exports more frequently than app updates allow.
Complexity. Building this super-flexible and extensible capability into Fieldmark while preserving security is something of an expensive ask. Instead, by isolating this complexity to the outside, we can run arbitrary data transformations on something like Cloudstor’s SWAN instance while preserving the security of the original data.
Money! We have so much to do that… as I was able to write an exporter… I did. When this feature is funded, we’ll bundle it with the app.
Regardless, we don’t expect most folks to have a working Python interpreter on their system, and so this will be an online-mediated process as they connect to MyBinder or Cloudstor, as the instructions we will soon9 write will instruct.
Technology Graph Discussion
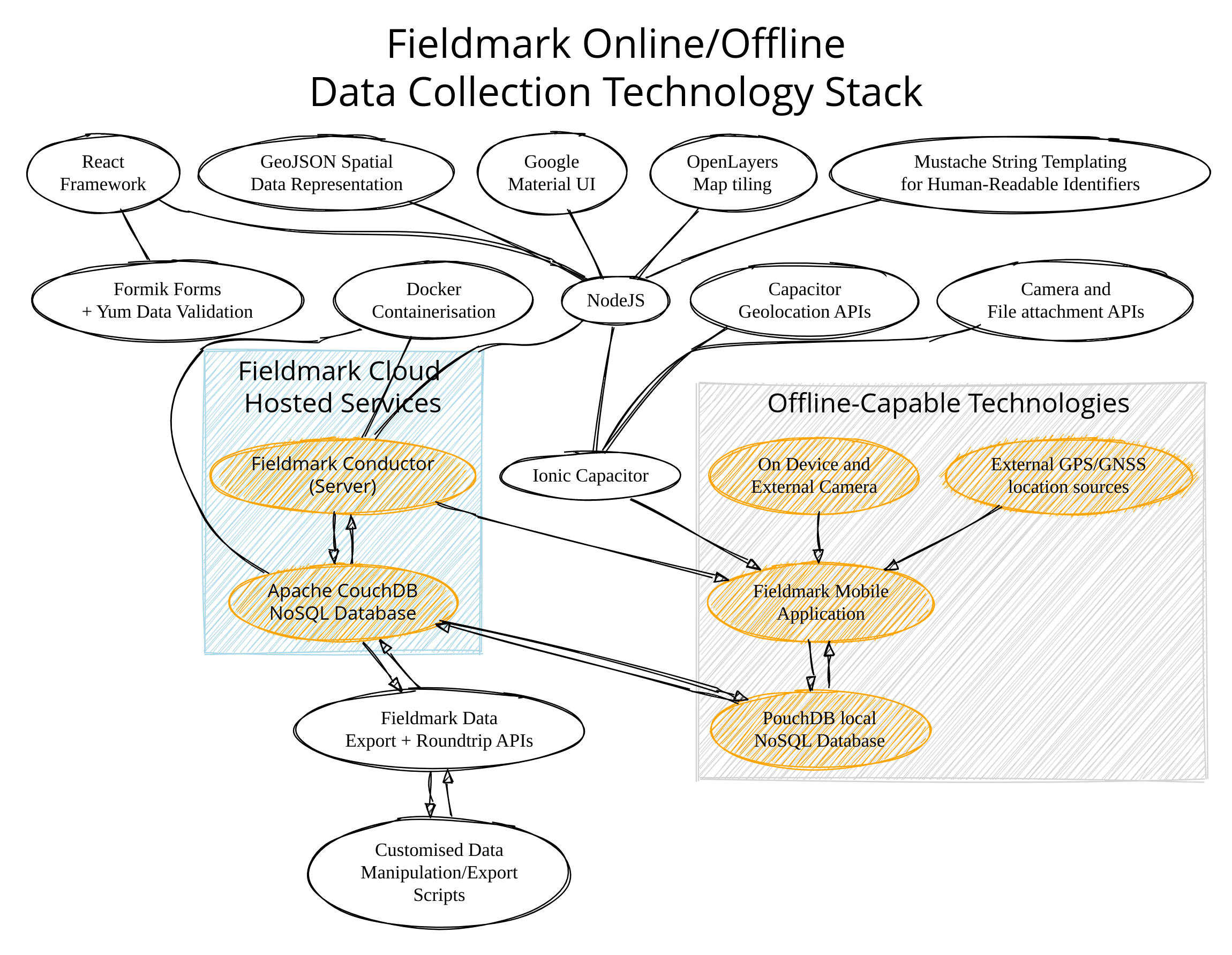
This 'semi-directed'10 graph shows how:
various technologies relate to our online/offline stuff;
gives a rough11 network topology; and
shows most (ish) of the high-level dataflows12 as communications between technological components.
Pragmatically, we have 5 major components:
The Fieldmark web-app: the app, itself, is written in Javascript (NodeJS ← React ← Formik ← Yum, Material UI, OpenLayers, Capacitor, Moustache). When presented on the browser, the browser receives a static site (HTML + compiled/minified JS + CSS + binary assets). The app uses PouchDB as a local, offline-capable, NoSQL datastore. It reaches out to our server (we call it the Conductor) to generate a JWT authentication token.
Our lightweight server, the Conductor, handles role management and authentication. It however, does not perform data exchange. The Conductor mints tokens, will eventually be able to moderate, edit, and create notebook designs, and will handle being a wrapper for our CouchDB datastore for other clients and non-Fieldmark users.
PouchDB uses the JWT token to replicate with a central Apache CouchDB datastore running in a Docker container13. The reason we chose CouchDB/PouchDB was because full replication (copy+sync) running in an 'eventual synchronisation' state (i.e. when the database can see the network again) was very exciting to us. We didn't have to write an offline-capable data synchronisation protocol.
Once all notebook metadata and data are synchronised, a properly authenticated user can load visible14 notebooks and visible records. Once this initial sync is performed15 the app is entirely equipped for offline fieldwork.
The Fieldmark mobile app is all of the above, except instead of NodeJS, Ionic’s CapacitorJS transpiles the javascript + extra bits into native code for iOS and Android. Pragmatically, it’s the same technology used by Electron to wrap a web browser and an extremely specific set of pages in an executable wrapper. As a hybrid native app, however, we can access the device-specific APIs for geolocation, camera, and Bluetooth — functionality critical for arbitrary workflows. Capacitor offers many plugins in this vein.
Roundtrip and Export scripts16 are presently written in Python and connect directly to the CouchDB servers. By using our own library, we can translate the form -> record -> revision -> attribute-value-pair NoSQL appropriate format of our internal datastore into dataframes appropriate for manipulation and export. These scripts can create new revisions (changing field values and record metadata like deleted flags) as well as exporting single entries or an entire workflow's datastore. Once in a more computable format, my scripts then rename photos and files, organise everything, and export to csv, xlsx, KML, and GeoJSON.
Stuff I’m reading
Quill & Still: Sophie Nadash And The Quite Nice, Very Cozy Divine Transmigration is an utterly lovely academic power fantasy that reminds me of Graydon Saunders’ Commonweal series. If you like web serials and you’re an academic, I suspect you’ll identify quite strongly with the protagonist.
Patrick McKenzie on bank branches.
A short story called ‘Recipe’ that also features an academic somewhat down on their luck.
A travelogue of the Nevada National Security Site (Parts 1-3 currently posted).
An interesting look at the techniques of ‘InnerSource’ (software development as applied to enterprise protocol and procedures and how to engage external contributors.
The White Tree of Gondor: A brief overview of Modern Ukrainian SF&F.
As originally planned…
Presently via Safari, but we’re working on it.
Penny’s contribution: ‘Let us not speak of approval in order to hold meetings about prepping field work...’
Wireless access points are also very handy for syncing at the end of the day, or while in transit between sampling sites. The MQ groundwater folk (currently up to 90 records!!) brought a wireless access point and it is serving them well.
Don’t bring laptops into the dirt. I did so on a dig in Israel and it was unwise. Necessary, but unwise.
It is so odd typing that in the same sentence as FAIMS 2 after a year and a half of FAIMS3…
So long as you don’t ask when…
Please, let us not speak of security. There is none here. The word I kept chanting was ‘Airgap’.
Hah!
This is not a real term, but some of the lines have `dir=none` and some of them are directed. This is not a usefully computable graph. It does, however, communicate the concepts that I want to communicate in a sufficiently fuzzy way to not give an incorrect sense of precision. (And creating a software bill of materials would not be an effective communication in this instance.)
The authentication flow is not pictured.
I apologise to my old lecturers (and to past-me who taught the bloody unit as well) at RIT for this mashup of a bunch of visualisation types. What do you mean I sound defensive?
After FAIMS 2, I have well learned my lesson about containerisation from the start. Making changes to the host OS to run a single app is… very 2012. It means that I can run many servers from one server with minimal tooling. That tooling is not expressed here.
Talk to us if you have highly sensitive data needs before you make the notebook.
Which may take a few minutes of rather anxious waiting without feedback right now. We know it’s a problem. We’re working on it.
To this nightmare, I can only shout to the heavens: ‘It’s ALIVE!’.
For more news, subscribe!

